-
AWSKRGU 서버리스 1월 소모임 후기🤔 개인 회고 2023. 1. 22.


발표 주제- 이상희 (AWS Solution Architect): Serverless 를 이용한 Multi-tenancy 서비스 만들기
- 이상현 (AWS Serverless Hero / Mirror CEO): Going Fully Serverless In Real World
1월 10일 AWS 한국 사용자 모임 커뮤니티 내 서버리스 소모임에 참석하면서 그동안 회사에서 AWS Lambda, Glue, Kinesis 와 같은 여러 서버리스 아키텍쳐를 사용해보면서 개인적인 궁금증이 많았는데 이번 서버리스 밋업을 통해 다른 개발자 분들은 AWS의 서버리스 서비스들을 사용하면서 어떤 것들을 고민했는지 간접적으로 체험 해 볼 수 있었다.
세션을 들으면서 개인적으로 공부하고 알게된 내용 위주로 정리를 해보았다.
세션1 : Serverless 를 이용한 Multi-tenancy 서비스 만들기
첫번째 세션은 AWS 서버리스 서비스들로 구성된 환경에서 multi-tenancy 서비스를 구축하기위한 방법에 대해 알수있었다.
테넌트(tenant, 사용자)란?
일반 유저, 프리미엄 유저와 같이 유저를 여러 그룹으로 관리해야 할 때, 유저를 구분하는 유저의 타입이라고 생각
멀티 테넌시(multi-tenancy) 서비스란?
단일 소프트웨어 인스턴스로 서로 다른 여러 사용자 그룹에 서비스를 제공할 수 있는 소프트웨어 아키텍처를 말한다. 보통 멀티 테넌시(multi-tenancy) 서비스를 아파트 건물에 비유를 하는데, 아파트 내 세입자들이 전기와 수도와 같은 시설은 한 아파트에 설치 되어있는 가스관, 수도관 같은 기반 시설을 서로 공유하듯이 멀티 테넌시(Multi-tenancy) 아키텍쳐도 이런 인스턴스 공유의 측면에서 같은 접근 방식을 가진다. 오늘날의 대부분의 서비스로서의 소프트웨어(Software-as-a-Service, SaaS) 제품이 멀티테넌트 아키텍처의 예
멀티 테넌시(multi-tenancy) 서비스가 왜 필요할까?

단일 테넌시(single-tenancy) 서비스 에서는 각 테넌트 마다 별도의 애플리케이션 과 DB 인스턴스를 가지고 있다. 이렇게 되면 테넌트 마다 격리된 환경을 구성받기 때문에 보안과 같은 측면에서 장점이 있지만, 각 테넌트는 자신이 할당받은 인프라를 일일히 관리해야 한다.
일부에서는 만약 고도로 민감한 데이터를 다루는 애플리케이션의 경우, *크로스 테넌트 공격(Cross-Tenant Attack)과 같은 위험이 있기 때문에 멀티 테넌시 아키텍쳐보다 단일 테넌시 아키텍쳐가 더 적합 할 수 있다고 한다.
그런데 또 일부에선 *크로스 테넌트 공격(Cross-Tenant Attack)은 따로 걱정할 필요가 없는 수준이라고 보는 의견도 있다고 한다. 미국 국가안보국의 2020년 클라우드 취약점 보고서에 따르면, 퍼블릭 클라우드 제공업체 중 어디서도 크로스 테넌트 공격이 발생했다는 기록이 없었고 크로스 테넌트 공격(Cross-Tenant Attack)으로 인한 리스크보다 부실한 액세스 제어 및 설정 오류로 인한 리스크가 더 크다고 판단했기 때문이다.
*크로스 테넌트 공격(Cross-Tenant Attack)이란?
같은 퍼블릭 클라우드의 다른 사용자로부터 발생할 수 있는 공격, 멀티 테넌시 환경에서는 서로 다른 테넌트가 같은 인스턴스를 공유하기 때 문에 외부가 내부의 어떤 사용자 그룹 내에서 다른 사용자 그룹을 공격 할 수있는 경우가 생길 수 있다.
블로그 | 크로스 테넌트 클라우드 공격을 걱정하지 않아도 되는 이유
핵심은 다음과 같다. 다른 클라우드 사용자로부터의 공격에 대한 방어는 매우 강력하며, 사용자가 집중해야 하는 위험은 다른 데 있다는 것이다.
www.ciokorea.com
멀티 테넌시(multi-tenancy)의 두가지 종류
1. silo model

멀티 테넌시 아키텍쳐는 각 테넌트가 인스턴스를 공유하는것에 주 초점이 맞추어져 있지만, 테넌트별로 완전히 격리된 환경을 제공해야 하는 경우에 대한 옵션도 존재하는데 그때 적용 할 수 있는 것이 바로 이 silo model 이다. 예시로는 AWS의 VPC 같이 테넌트 별로 완전 분리된 인스턴스 환경을 따로 구성 하는것이 있다.
단점 : 관리포인트가 늘어남, 테넌트가 늘어 날때 마다 자원이 배로 늘어나야 함.
2. pool model

각 테넌트가 인스턴스를 공유하는것에 초점을 맞춰 여러 테넌트가 하나의 자원을 공유하는 모델로 AWS 서비스에서는 tag기능을 활용하면 pool model을 적용 할 수 있다.
비용이 저렴하기 때문에 대부분 pool model 방식으로 서버리스 환경에서 멀티 테넌시 환경을 구성한다.
AWS Cognito 서비스
웹 및 모바일 앱에 대한 인증, 권한 부여 및 사용자 관리를 제공하는 서비스
사용자 풀, 자격 증명 풀이라는 두가지 주요 구성요소로 구성되어있다.
- 사용자 풀 : 앱 사용자의 가입 및 로그인 옵션을 제공하는 사용자 디렉터리
- 자격 증명 풀 : 기타 AWS 서비스에 액세스할 수 있는 권한을 부여
Amazon Cognito 사용자 풀 및 자격 증명 풀을 함께 사용 하는 예시

1. 앱 사용자는 사용자 풀을 통해 로그인 수행, 로그인 성공시 사용자 풀 토큰 획득
2. 자격 증명 풀을 통해 로그인 과정에서 얻은 사용자 풀 토큰을 AWS 자격 증명으로 교환
3. 앱 사용자는 AWS 자격 증명을 사용하여 Amazon S3, DynamoDB 등 다른 AWS 서비스에 액세스

cognito에 정한 tenent 별로 DynamoDB의 권한을 설정 할 수 있다.
전체 서버리스 아키텍쳐 구성도

이 상황에서 OPA 서비스를 사용하면 policy decision-making(정책 의사 결정)과정 과 Policy enforcement(정책 시행)을 분리할 수 있다.
만약 관리자 권한이 있는 사람만 사용자 리스트를 볼 수 있습니다. 라고 한다면, 여기에서 관리자 권한이 있는 사람인지 판단하는 부분은 정책 의사결정 부분이고 이 부분을 OPA로 하고, 사용자리스트를 보는 정책 시행 부분은 구현해둔 코드나 서비스에서 실행할 수 있도록 분리 할 수 있다는 것이다.
OPA 서비스의 특징
AWS 외부 리소스도 통합이 가능하다. => AWS의 보안정책과 GCP의 보안정책을 OPA로 한방에 관리를 할 수 있다.
AWS IAM의 RBAC(역할 기반 액세스 제어) 방식이아닌, PBAC(정책 기반 액세스 제어) 방식을 사용해서 더 세밀하고, 유연한 정책 의사 결정이 가능하다.Rego 라는 언어로 코딩을 하듯이 정책 의사 결정 로직을 구성 할 수 있다.
OPA를 이용한 의사 결정 로직 분리 예시



OPA 서비스를 Docker로 말아서 AWS Lambda에 띄우면, 의사 결정 로직 수행하는 부분까지 전부 서버리스 환경으로 구성할 수 있다.
OPA 관련 질문들
Q. OPA 서비스를 도커 컨테이너로 말아서 Lambda에 띄우게 되면, 느린 스타트 타임이 걸릴수 있을 것 같은데 이를 해결하기 위해서 어떻게 해야 할까요?
A. 맞습니다. 어쩌다가 찌르는 경우 최대 1분정도 소요되는 느린 이슈가 있다. 이는 Lambda 콜드스타트 문제 때문인데, 많이 찌를것 같다 싶으면, OPA 요청을 모아서 한번에 묶어서 보내거나, OPA 서비스를 Lambda에 띄우기보다는 컨테이너 띄우는 방식을 고려해야할것 같습니다.
Q. API GateWay에서 Lambda를 권한 부여자로 사용하면, 정책 의사 결정 부분을 분리 할 수 있는데 OPA와의 차이점이 있을까요?
A. OPA는 Rego라는 언어를 사용하는데 이 언어가 더 직관적이다. 그리고 외부 data.json 으로 롤을 따로 빼서 프리미엄 유저, 일반유저 구분해서 관리 하겠다하면 Lambda 권한 부여자로 그냥 롤을 외부 파일로 빼는 것 없이 사용하는 것 보다 좋을 수 있다.
세션2 : Going Fully Serverless In Real World
서버리스로 만들 수 있는 것들
사실 대부분의 서비스를 서버리스로 구성 할 수 있다.

서버리스로 만들 수 없는 것들
- CPU, 메모리 많이 사용해야 하는 부분
- 최대 5~10ms 응답이 보장되야 하는 부분
- JVM, C# 언어는 패널티 존재
- RDS, Cache, Search …. 와 같은 인프라도 완전한 서버리스로 구성하기는 힘들다.
- AWS AuroraDB의 경우 Serverless 옵션이 있기는 하지만, 진정한 의미의 서버리스가 아니다.(내부적으로 인스턴스가 떠있고, 그 인스턴스를 관리자가 신경 써야하면 완벽한 서버리스가 아니라고 생각한다.) 그래서 대안으로 AWS DynamoDB를 key-value Storage로 사용 할 수 있다.
그렇다면 왜 사람들은 서버리스로 전체 시스템을 구성하지 않는걸까?
그것은 기술의 문제가 아니라 인간과 조직의 문제일수있다.
서버리스를 도입하지 않는 이유중에 대표적으로 "Lambda에서 했더니 이게 안되요!" 이런 문제들이 있는데 이것은 사실 Lambda의 문제가 아닐 수 있다.
예를 들면, Lambda와 RDS 연결하면 max connection 초과 되는 문제를 자주 만날 수 있다. 만약 Lambda가 하나의 컨테이너라고 하면, 그 컨테이너를 수십 수백개 띄워 운영 할 경우 똑 같이 max connection 초과 되는 문제가 발생될 것이다. 따라서 이것은 Lambda 고유의 문제가 아니고, 트래픽을 어떻게 관리해야 할 지에 대한 부분으로 보아야 하는것이다.
또 Lambda에서는 local memory나 session storage를 사용 못하는지에 대한 의문이 들 수 있다.
어떤 서비스에서 local memory를 사용한다는 것은, 그 사용자는 반드시 그 contaioner나 instance에 다시 붙어야 한다는 것을 말한다.
이것은 해당 서비스가 statefull한 특성을 같는다는것 말하는 것이고, 따라서 scaling이 힘들다는것을 말하는 것이다.
예를들어 유저 10명이 각각 10RPS로 하나의 컨테이너에 붙어있었는데, 중간에 유저 1명이 20RPS로 사용량이 증가했다면 어떻게 해야 할까? 그 유저의 요청을 다른 컨테이너로 보내야 할것이다. 그런데 만약 그 유저의 state가 이전 컨테이너에 local memory에 저장되어있다면?
따라서 Lambda에서는 local memory나 session storage를 사용 못하는지에 대한 의문은 stateless한 서비스에서 statefull한 환경을 구성하고 싶어요! 라는 질문으로 바꾸어 생각해 볼 수 있는것이다. 만약 lambda를 statefull하게 구성해서 사용한다면, lambda 서비스에서 얻을 수 있는 scalablity의 이점을 버려야 한다는 것이다.
cf. CAP 이론
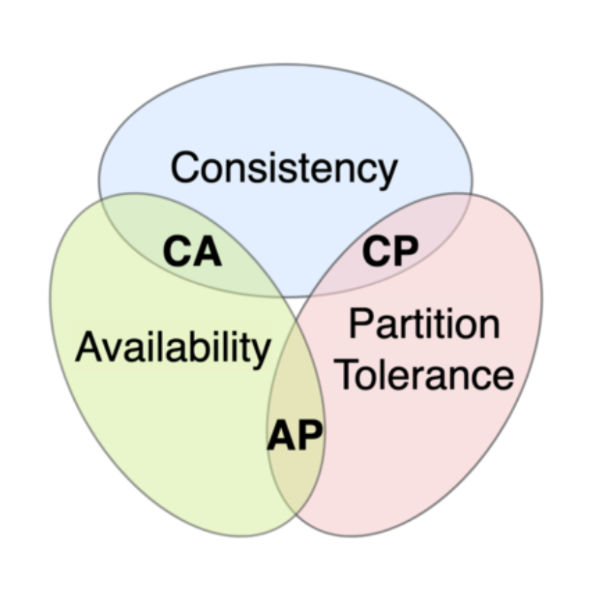
CAP 정리에 의하면 시스템은 일관성(Consistency), 가용성(Availablity), 분단 허용성(Partition torlerance) 세 가지 속성중에서, 두 가지만 가질 수 있다
일관성(Consistency) :
만약 DB가 A, B 2개의 Instance를 유지하고 있다면 A에 요청하든 B에 요청하든 동일한 값이 반환됨
가용성(Availablity) :클러스터의 노드 일부에서 장애(Down 등)가 발생하더라도 READ와 WRITE 등의 동작은 항상 성공적으로 리턴되어야 한다는 것
분단 허용성(Partition tolerance) :
만약 DB가 A, B 2개의 Instance를 유지하고 있고 만약 A와 B의 Instance간의 네트워크에 장애가 발생한 상황에서, 유저는 A DB에서 쿼리를 하면 Instance A는 B의 상태를 알지 못하지만 A 자체만으로 동작을 해야한다는 뜻
서버리스 관련 질문
Q. 서버리스 환경에서는 단위테스트나 E2E테스트 같은 테스트용 환경은 어떻게 구성 할수있을까요?
A. E2E 테스트는 사실상 힘들다. 그래서 production 환경과 동일한 스펙을 가진 별도 staging 환경을 구성 한 후 테스트를 staging 환경에서 실제 요청을 보내는 방식으로 진행 했다. 그리고 단위/유닛 테스트의 경우, Lambda에 정의한 기능하나가 정해진 인풋에 정해진 아웃풋이 나오는지 테스트하는 방식으로 진행 했다.
Q. API별로 별도 Lambda로 각각 쪼개면 배포할때마다 Lambda도 여러번 배포하고, CPU 사용량 프로파일링 할때도 다 따로봐야하는데 번거로울것 같다.
A. 하나의 Lambda에 API별로 함수를 여러개 만들어서 사용했다. 프로파일링 같은 경우는 Lambda 로그를 활용했다.
Q. 서버리스 환경에서 여러 서비스들 간의 네트워크 타임 아웃 같은 것 핸들링 하려면 어떻게 해야할지 (API 게이트웨이 타임아웃, 람다 타임 아웃 설정 방법이 각각 다르기도 하고, 타임아웃 걸렸을때 이렇게 행동해라 하고 지정해야 하는데 그런 기능을 지원 안해주는 경우 어떻게 했는지)
A. 시스템 내부적으로 코드에 타임아웃을 걸어두고, 코드에 지정된 시간동안 처리를 못했을때에 대한 처리도 코드레벨에서 진행했다.
출처
https://everycloudhasasilverlining.tistory.com/36
OPA(Open Policy Agent)란?
생각보다 OPA에 대해서 들어본 사람이 없는 것 같다. 특히 국내에서는 확산이 많이 안된거 같지만, 해외 벤더사들은 많이 사용하고있다... 클라우드, 쿠버네티스, MSA, 메타버스, 블록체인 등등 IT
everycloudhasasilverlining.tistory.com
https://blog.plainid.com/why-role-based-access-control-is-not-enough
PBAC vs RBAC: Why Role Based Access Control is not Enough
For modern enterprises, Role Based Access Control (RBAC) doesn't provide the granularity & control needed for Authorization. Here's why PBAC has the edge.
blog.plainid.com
https://d1mmk10lcvudwp.cloudfront.net/
Multi-tenant Cognito
The goal is to secure a Tenant; client and server side, using IAM and fine grained access control Below describes how this achieved when new users sign up for an organisation
d1mmk10lcvudwp.cloudfront.net
Amazon DynamoDB: Amazon Cognito ID를 기준으로 DynamoDB에 대한 항목 수준 액세스 허용 - AWS Identity and Access M
Amazon DynamoDB: Amazon Cognito ID를 기준으로 DynamoDB에 대한 항목 수준 액세스 허용 이 예제는 Amazon Cognito ID를 기준으로 MyTable DynamoDB 테이블에 대한 모든 액세스를 허용하는 아이덴티티 기반 정책을 생
docs.aws.amazon.com
https://dongwooklee96.github.io/post/2021/03/26/cap-%EC%9D%B4%EB%A1%A0%EC%9D%B4%EB%9E%80/
CAP 이론이란? | 개발자 이동욱
CAP 정리 CAP 정리에 의하면 시스템은 일관성(Consistency), 가용성(Availablity), 분단 허용성(Partition torlerance) 세 가지 속성중에서, 두 가지만 가질 수 있다는 것이다. 위의 그림에서 볼 수 있듯이, Consiste
dongwooklee96.github.io
'🤔 개인 회고' 카테고리의 다른 글
23년 1월 회고 (0) 2023.02.06 [글또 8기] 삶의 지도 (0) 2023.01.29 12월 회고 및 2022년 회고 (0) 2023.01.01 2022년 11월 - 인프런 퇴근길 Node.js 밋업 회고 (0) 2022.12.05 2022년 11월 회고 (0) 2022.12.03