-
[Real MySQL] 인덱스 (2) - B-Tree 인덱스✍️ 개인 스터디 기록 2022. 12. 12.

옛다~! 너가 찾는 데이터 B-Tree 인덱스
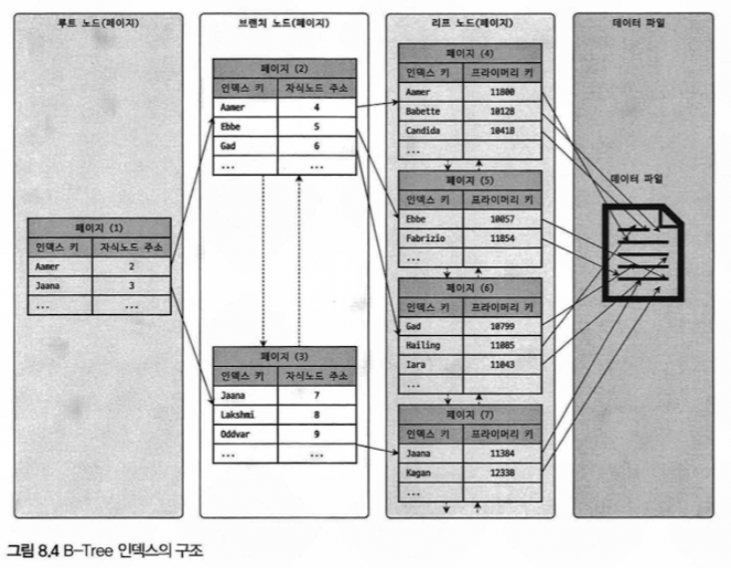
제일 상단에 루트노드 부터 시작해서 제일 하단 리프노드 까지 인덱스 페이지별로 나뉘어져 있다.
인덱스로 정한 키값이 정렬된 상태로 되어있다는 점이 중요하다.
실제 데이터파일의 경우 정렬이 되어있지 않고 임의의 순서로 저장된다.
인덱스테이블에는 키값만 저장되어있기 때문에 나머지 컬럼 정보를 가져오기 위해서는 실제 데이터 파일에서 해당 레코드를 찾아와야한다.
InnoDB 엔진에서는 세컨더리 인덱스에서 B-Tree 탐색이 2번 일어난다.
InnoDB 엔진에서는 아래 그림처럼 리프노드에서 프라이머리 키가 실제 데이터의 주소값 역할을 하는데,
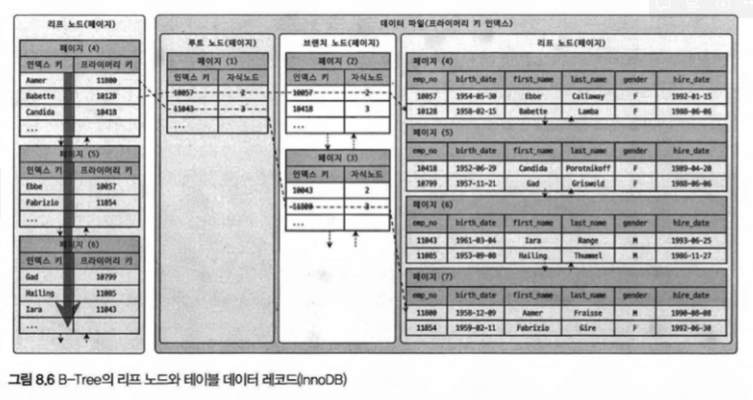
그렇기 때문에 리프노드에서 프라이머리 키를 찾았으면, 찾은 프라이머리 키로 실제 데이터를 찾기 위해 프라이머리 키 인덱스 B-Tree를 또 탐색하는 과정이 일어난다.(프라이머리 키 인덱스에는 리프노드에 실제 데이터가 들어가 있다. = 클러스터링 인덱스)
B-Tree 인덱스 키 추가
B-Tree 자료구조의 특성이 어떻길래 데이터를 추가 할때 많은 비용이 든다는 것일까?
B-Tree 자료구조에서 데이터를 추가 할때 리프노드의 갯수가 가득차지 않았다면 오름차순으로 트리를 탐색하며 적절한 공간에 데이터를 추가 하기만 하면 된다. 그런데 리프노드의 갯수가 가득찼을 경우에는 노드의 분리가 일어나야하기 때문에 비용이 많이 든다.
리프노드 공간이 널널 할 경우: 트리 탐색하면서 적절한 자리 찾아서 넣으면 됨
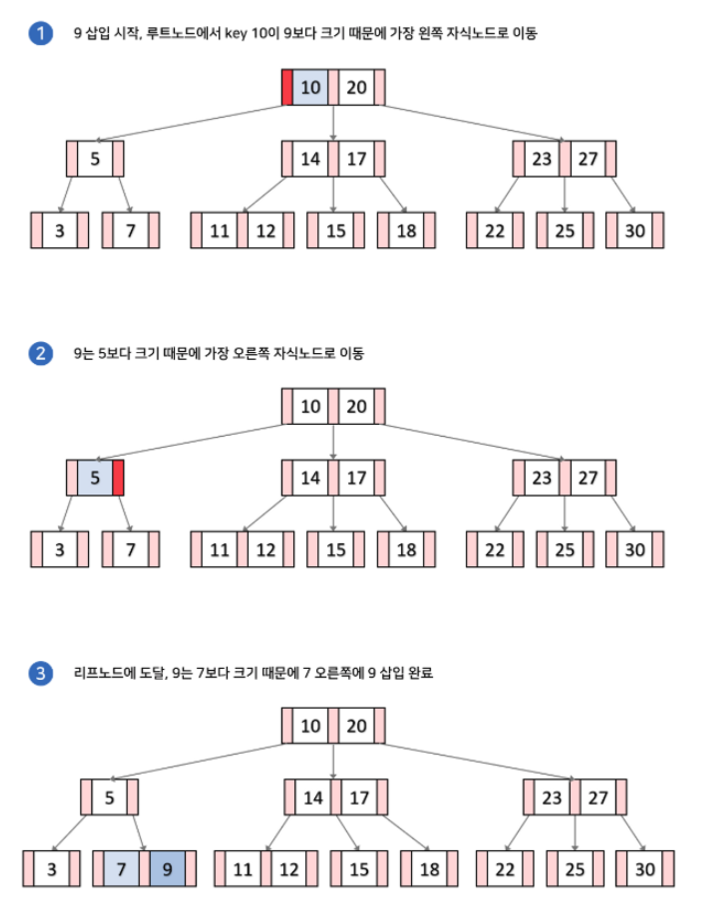
리프노드 공간이 부족할 경우 ⇒ 노드의 분리가 일어남 ⇒ 상위 노드에까지 영향을 줌
(아래 예시 그림에서 각 노드가 최대로 가질 수 있는 키의 갯수는 2개라고 하자)

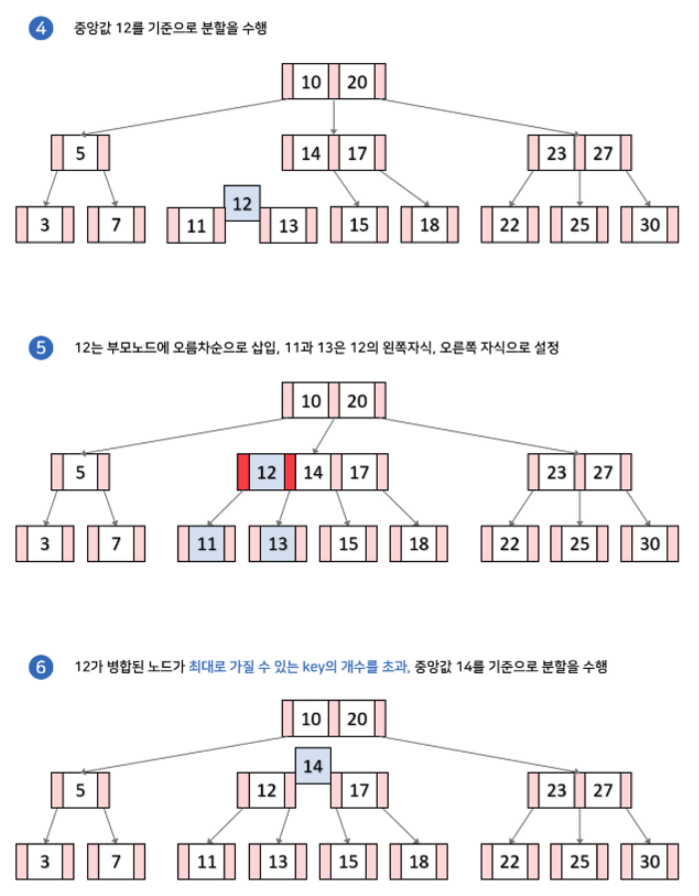
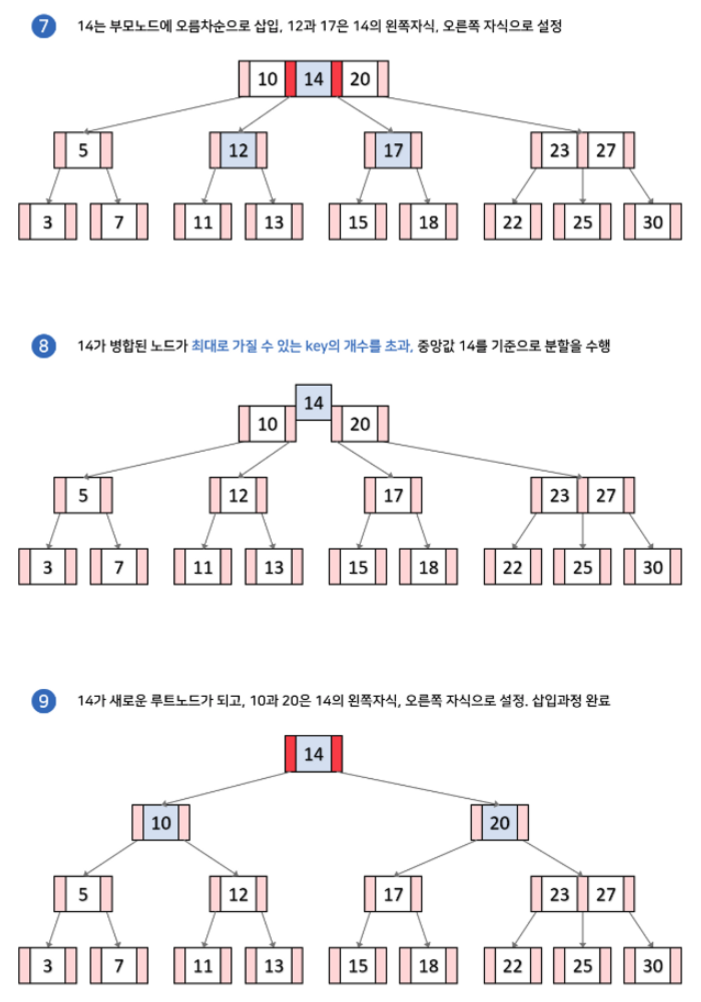
위 그림으로 보면 리프노드의 공간이 널널 할 경우 3단계면 끝나지만, 만약 리프노드의 공간이 꽉차서 노드 분리가 일어날경우 9단계 만에 삽입 과정이 일어난것을 볼 수 있다. 그렇다면 Insert의 대략적인 비용은 어떻게 될까?
대략적인 INSERT 비용 계산
이 처럼 B-Tree에 데이터를 추가하는 과정은 인덱스 테이블을 메모리에서 불러오고 데이터를 쓰는데 부가 작업이 많은데 대략적으로 다음과 같은 비용이 든다.
- 인덱스가 없는 테이블에 그냥 Insert 하는 비용이 1이라고 하면
- 인덱스가 있는 테이블에 Insert 하는 비용은 인덱스 컬럼 1개당 1.5가 추가된다고 계산을 한다고 한다.
인덱스 컬럼이 3개인 테이블에 데이터 1개 Insert 비용 = 1.5*3 + 1 = 5.5 정도로 예측한다.
B-Tree 인덱스 키 삭제
원래 B-Tree 삭제의 경우, 삭제하려는 데이터가 리프노드에 있는지 아닌지 에따라, 현재 노드의 key수가 최소인지 아닌지에 따라 복잡한데, B-Tree 인덱스 테이블의 경우 해당 키값이 저장된 리프노드를 찾아서 그냥 삭제 마킹만 수행 한다.(아마도 실제 데이터가 모두 리프노드에만 존재하기 때문일것 같다. 🤔) 이때 디스크 쓰기 I/O작업이 발생하고, 이 작업은 버퍼링되서 나중에 한번에 실행될 수 도 있다고 한다. 삭제 마킹된 인덱스 키 공간은 계속 방치되거나, 나중에 재활용된다.
B-Tree 인덱스 키 변경
먼저 이전 키값을 삭제 한 후 다시 새로운 키값을 추가하는 형태로 동작한다.
B-Tree 인덱스 키 검색
루트노드 부터 리프노드까지 트리 탐색이 일어난다.
😱 검색 시 주의할 점
- 어떤 걸 검색할지 주의: 인덱스 키값을 변형한 결과로 검색하거나 나 앞부분이 아닌 뒷부분을 가지고 검색 할 경우 해당 값은 B-Tree내에 없으므로 B-Tree의 빠른 검색을 활용할 수 없으니 주의 해야한다.
- 인덱스 잠금을 고려할 것: InnoDB의 잠금은 레코드 자체를 잠그는 것이 아니라 인덱스를 잠그는 방식으로 되어있다. 그래서 인덱스가 적절하게 설정되어있지 않을 경우 UPDATE를 하기 위해 너무 많은 인덱스를 잠구거나, 아예 전체 테이블을 다 잠궈버릴 수 도 있다. 그렇게 되면 동시성이 상당히 떨어져 한 클라이언트가 한 세션에서 UPDATE를 수행하는 중에 다른 클라이언트는 그 테이블을 업데이트 하지 못하고 기다려야 하는 상황이 발생할 것이다. 그렇기 때문에 이 UPDATE문으로 너무 많은 인덱스가 잠기는게 아닐지도 고려해 인덱스를 설계 해야 한다.
인덱스 페이지란?
InnoDB 스토리지 엔진은 데이터와 인덱스를 페이지 단위로 저장한다.
페이지는 읽기, 쓰기 작업의 기본단위가 된다.
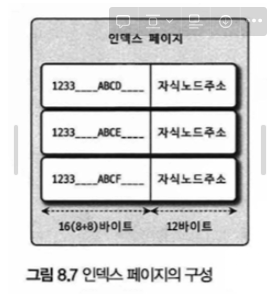
인덱스 키값의 크기가 클수록 B-Tree 인덱스 페이지의 자식노드 갯수는 줄어든다.
⇒ 검색을 위해 더 많은 페이지 탐색이 들어가게 되고 검색 성능이 저하된다.
B-Tree 인덱스 사용에 영향을 미치는 요소
1. B-Tree 깊이
인덱스로 지정한 키값의 평균적인 크기가 클 경우 페이지가 늘어난다고 했는데 이는 B-Tree 관점에서 보면 깊이가 늘어나는 것이다.
B-Tree 깊이가 깊어지면 그만큼 디스크의 랜덤 I/O가 늘어난다.
2. 선택도(기수성, 카디널리티)
카디널리티란 유니크한 값의 갯수를 말한다.
인덱스로 지정한 키값의 카디널리티가 작으면 한번 검색으로 많은 양의 불필요한 데이터도 함께 딸려오게 되고, 그 결과 딸려온 많은 데이터에 대해 다시 한번 각각 검색을 수행해야 한다. 😱

썩은 고구마를 찾기 위해 고구마를 하나 뽑았는데 고구마 밭 전체가 딸려나오는게 좋을까? 아니면 몇개만 딸려 나오는게 좋을까? 🧮 카디널리티 손익분기점 : 전체 테이블의 20~25% 🧮
인덱스를 통해 레코드를 1건 읽기 작업을 수행하는것은 테이블에서 직접 레코드를 읽는것보다 4~5정도 비용이 더 든다고한다. 그래서 인덱스를 통해 읽어야 할 레코드 건수가 전체 테이블 레코드의 20~25%를 넘어서면 오히려 인덱스를 설정하지 않고 테이블을 모두 직접읽어서 필요한 레코드만 필터링 하는 방식이 더 효율적이다.
(물론 이런경우, MySQL 옵티마이저가 기본적으로 힌트를 무시하고 테이블을 직접 읽는 방식으로 처리한다.)
'✍️ 개인 스터디 기록' 카테고리의 다른 글
[TS] tsconfig.json 변환 할 파일 지정 과 변환 결과 설정 옵션 (files, include, exclude, outDir) (1) 2023.01.07 [Real MySQL] 인덱스 (3) - B-Tree 인덱스를 통한 스캔 방식들 (0) 2022.12.12 [Real MySQL] 인덱스 (1) - 인덱스란? 인덱스의 구분 (0) 2022.12.12 모던 자바스크립트 Deep Dive 퀴즈 리스트 (0) 2022.12.02 [NodeJS] C10K Problem 과 NodeJS (1) 2022.11.27