-
테스트 데이터 생성
DELIMITER $$ DROP PROCEDURE IF EXISTS gen_data$$ CREATE PROCEDURE gen_data( IN v_rows INT ) BEGIN DECLARE i INT DEFAULT 1; create table tb_test1( no bigint, col1 varchar(100), col2 varchar(100), col3 varchar(100) ); WHILE i <= v_rows DO INSERT INTO tb_test1 (no , col1, col2 , col3 ) VALUES(concat(i), concat('col1-',i), concat('col2-',i), concat('col3-',i)); SET i = i + 1; END WHILE; END$$ DELIMITER ; call gen_data(1000000); create table tb_test2 as select * from tb_test1; CREATE INDEX idx_col1 ON tb_test1 (col1); CREATE INDEX idx_col1 ON tb_test2 (col1);1. Nested Loop Join
조인의 연결 조건이 되는 컬럼에 모두 인덱스가 있는 경우 사용되는 조인 방식
중첩 for 문 방식
https://www.youtube.com/watch?v=pJWCwfv983Q&t=88s
explain select * from tb_test1 a INNER JOIN tb_test2 b ON a.col1=b.col1 -- 두 테이블 모두 col1 에는 인덱스 설정 된 상태 where a.no > 1 and b.no > 2;
Nested Loop Join의 경우 실행계획의 Extra 컬럼에 별도 표시되는 항목이 없다.

😱 Nested Loop Join에서 주의 할 점
어떤 테이블이 먼저 액세스 되느냐에 따라서 속도의 차이가 크게 날 수 있다. 그렇기 때문에 어느 테이블을 드라이빙 테이블로 설정 하는지, 드라이빙 테이블이 너무 많은 데이터를 읽는것은 아닌지 확인 하는 것이 중요하다.
-- 테스트1 네스티드 루프조인, 드라이빙 조건에 걸리는 테이블 row 많은 경우 -- 38s explain select * from tb_test1 a INNER JOIN tb_test2 b ON a.col1=b.col1 where a.col1 >= 'col1-100' and b.col1 >= 'col1-100'; -- 테스트2 네스티드 루프조인, 드라이빙 테이블 row 적은 경우 -- 14ms select * -- 35.6ms from tb_test1 a INNER JOIN tb_test2 b ON a.col1=b.col1 where a.col1 >= 'col1-999900' and b.col1 >= 'col1-100';드라이빙 테이블의 검색 조건에 걸리는 데이터가 많은 경우(테스트1 약 999,900개) 적은 경우보다 처리에 속도가 오래 걸리는 것을 확인 할 수 있다.
2. Block Nested Loop Join
⇒ 드리븐 테이블의 연결 조건에 인덱스를 사용할 수 없는 경우 사용되는 조인 방식

드리븐 테이블 연결 조건에 인덱스를 사용할 수 없는 경우, Driving 테이블의 추출 건수만큼 Driven(Inner) 테이블 Full Scan 을 반복적으로 스캔을 해야하는 상황이 발생하는데 이러한 문제를 개선 하고자 내부적으로 내부적으로 메모리 버퍼를 활용하는 방식

드라이빙 테이블 row 하나 하나 마다 드리븐 테이블을 순회 할 필요 없이
드라이빙 테이블 row 여러개를 메모리에 저장해두고, 드리븐 테이블의 데이터를 한번 가지고 온 다음, 메모리에서 드라빙 테이블과 드리븐 테이블 데이터를 조인처리
데이터 스캔 횟수가
드라이빙 테이블 row 갯수 X 드리븐 테이블 row 갯수 당 조인 1번에서
(드라이빙 테이블 row 갯수 X 드리븐 테이블 row 갯수) / 버퍼크기 당 1번으로 조인 횟수가 줄어들게 된다.
실행 계획 확인
explain select * from tb_test1 a JOIN tb_test2 b on a.col2=b.col2 // 인덱스가 아닌 컬럼이 조인의 연결 조건으로 사용 되는 경우 작동 where a.no < 10 and b.no > 10;MySQL 5.7 버전의 경우

MySQL 8.0.20 버전 부터 더이상 사용되지 않고, 해시조인 알고리즘이 대체되어 사용된다.

3. Hash Join
MySQL 8.0.20 버전 부터 드리븐 테이블의 연결 조건에 인덱스를 사용할 수 없는 경우,
Block Nested Loop Join대신 사용되는 조인 방식
어느 테이블로 해시를 구성했는지 확인하기
explain format=tree select * from tb_test1 a JOIN tb_test2 b on a.col2=b.col2 // 인덱스가 아닌 컬럼이 조인의 연결 조건으로 사용 되는 경우 작동 where a.no < 10 and b.no > 10;explain format=tree 로 실행계획을 분석할때, 제일 하단에 명시된 테이블이 해시로 구성된 테이블이다.
이렇게 해시로 구성되는 테이블을 빌드테이블, 구성된 해시와 조인되는 테이블을 프로브 테이블이라고 한다.
-> Filter: (b.col2 = a.col2) (cost=124311.64 rows=37278) -> Inner hash join (<hash>(b.col2)=<hash>(a.col2)) (cost=124311.64 rows=37278) -> Filter: (b.`no` > 10) (cost=3.43 rows=334) -> Table scan on b (cost=3.43 rows=10034) -> Hash -> Filter: (a.`no` < 10) (cost=1027.65 rows=3344) -> Table scan on a (cost=1027.65 rows=10034)
메모리(조인버퍼)의 크기가 조인처리해야할 데이터보다 작을 경우, 위 그림 처럼 빌드 테이블과 프로브 테이블의 데이터를 여러 청크를 구성해 나누어 조인 작업을 진행한다.
Nested Loop Join과 성능 비교

위 그림에서 A 지점은 MySQL 서버가 첫번째 레코드를 찾아낸 시점, B는 마지막 레코드를 찾아낸 시점이다. 해시조인의 경우 첫번째 지점을 찾기 까지는 오래걸리지만, 전체적인 실행시간이 Nested Loop Join 보다 적게 걸리는 것을 확인 할 수 있다.
MySQL 서버는 조인 조건의 인덱스 컬럼이 없거나, 조인 대상 테이블 중 일부의 레코드 건수가 매우 적은 경우등에 대해서만 해시 조인 알고리즘을 사용하도록 설계 되어있다.
일반적인 OLTP 환경의 경우 빠른 응답속도가 중요하기 때문에 해시조인이 더 빠르다고 옵티마이저 힌트를 사용해서 강제로 쿼리 실행계획을 해시 조인으로 유도하는 것은 좋지 않다.
정리
조인 조건 컬럼에 인덱스 있다면 인덱스네스티드 루프 조인 → 인덱스 못쓰는 경우 “블록” 네스티드 루프조인 → 더 빠른 해시 조인으로 대체
4. Batch Key Access JOIN(BKA JOIN)
Multi Range Read 방식을 적용한 조인 방식
MMR 방식이란?
Multi Range Read(MRR)는 메모리 버퍼를 사용하여 Random I/O를 Sequential I/O로 처리할 수 있도록 도와주는 기능
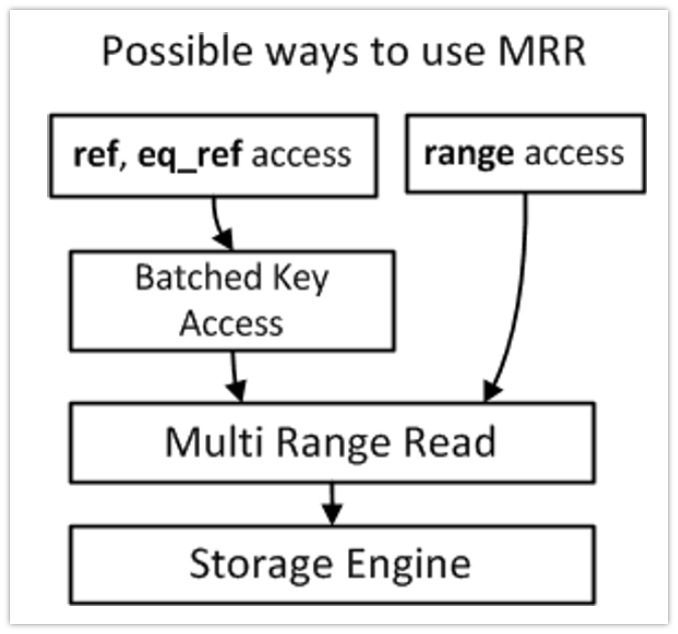
MMR의 경우 BKA 조인, Index range scan 에서 사용될 수 있다. 1. Index range scan 에서 MMR이 사용되는 경우
Non-Clustered Index에서 Range Scan을 사용하여 테이블의 행을 읽게 되는 경우 테이블에 대한 랜덤 디스크 액세스가 많이 발생할 수 있게 된다.

Index range scan에서 MMR이 적용되지 않은 경우 MMR기능이 켜진 경우 버퍼 내에서 한번 데이터의 정렬이 일어나기 때문에 랜덤 I/O를 줄일 수 있다.

Index range scan에서 MMR이 적용된 경우 Index range scan 에서 MMR 기능 사용해 보기
[TEST1] MMR 사용, Non-Clustered Index에서 Range Scan
SET profiling=1; -- MMR 사용, Non-Clustered Index에서 Range Scan -- 조회되는 건수에 따라서 MRR 동작 대신 Index Condition Pushdown 이 동작될 수 도 있는데 테스트를 위해 그 기능 off set optimizer_switch='index_condition_pushdown=off'; set optimizer_switch='mrr_cost_based=off'; -- MMR on 설정 set optimizer_switch='mrr=on'; select * from tb_test1 force index(idx_col1) where col1 between 'col1-1' and 'col1-900000'; SHOW profiles;
MMR 옵션이 켜진 경우, Extra 컬럼에 정보가 표시 된다. → 17초 소요
[TEST2] MRR 사용 X, Non-Clustered Index에서 Range Scan
SET profiling=1; -- MMR 사용 x, Non-Clustered Index에서 Range Scan set optimizer_switch='index_condition_pushdown=on'; set optimizer_switch='mrr_cost_based=on'; set optimizer_switch='mrr=off'; explain select * from tb_test1 force index(idx_col1) where col1 between 'col1-1000' and 'col1-500000'; SHOW profiles;
→ 16초 소요
?? 오히려 MMR 기능을 켰을때 더 시간이 걸렸는데, SSD라서 랜덤 읽기 I/O를 줄인다고 해도 별 성능 이점이 없었던 것일까?
4. Batch Key Access JOIN(BKA JOIN)에서 사용되는 경우
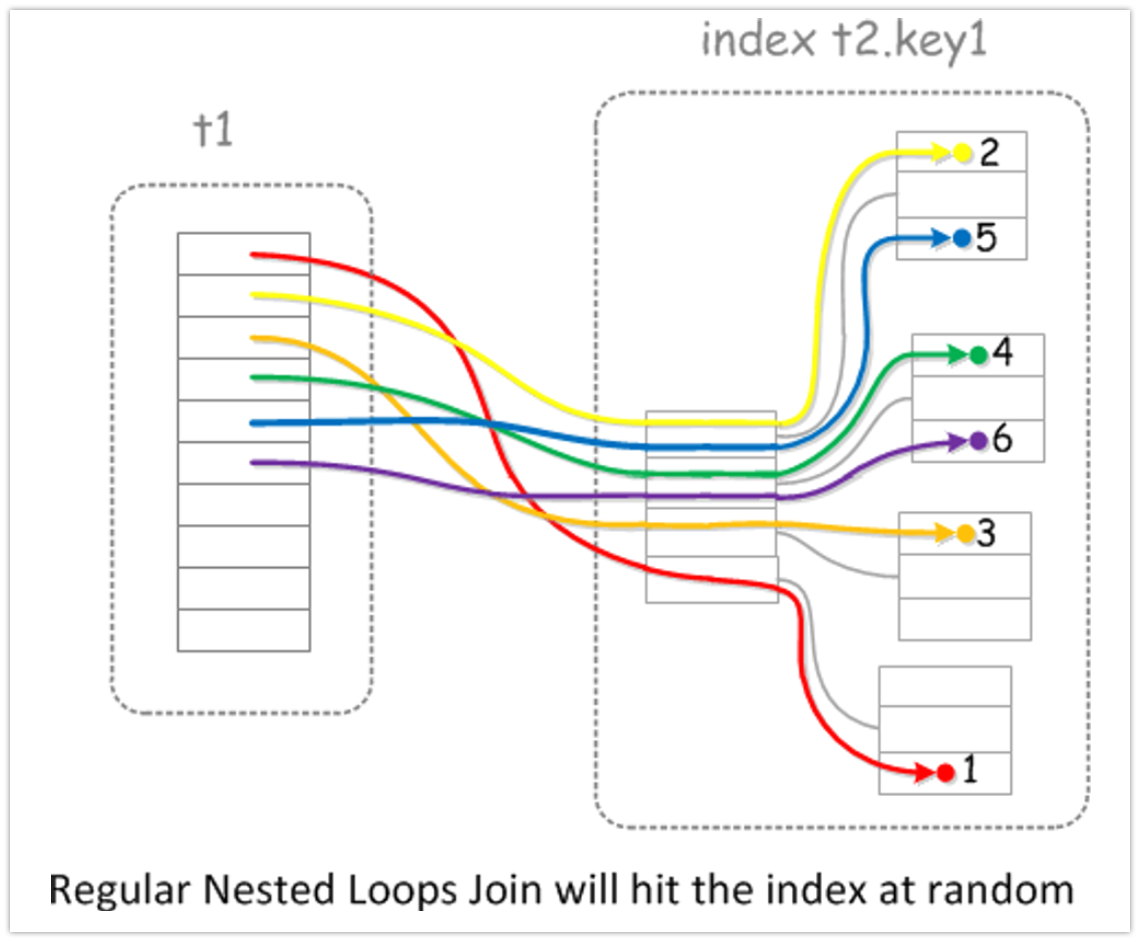
일반적인 Nested Loop 조인(NLJ) 의 경우 Driving Table(선행 테이블)에서 조회되는 값으로 조인되는 Driven Table(Inner 테이블,후행 테이블) 을 접근하게 되며 조인시 데이터 저장 순서대로 조회를 하는 것이 아니기 때문에 랜덤 액세스, 랜덤 I/O가 발생되게 된다.

BKA 조인의 경우 메모리에서 드라이빙 테이블에서 읽어온 데이터를 부가적으로 정렬하기 때문에 랜덤 I/O를 줄일 수 있다.
하지만 이 부가적인 정렬이 오버헤드로 작용 할 수 도 있기 때문에 무조건적으로 성능의 이점이 있는것은 아니다.
출처
https://hoing.io/archives/24491
MySQL - Block Nested-Loop and Batched Key Access Joins
hoing.io
'✏️ 스터디 모음집 > RealMySQL 스터디' 카테고리의 다른 글
Docker-Compose로 InnoDB 클러스터 구축 실습 환경 구성하기 (0) 2023.07.02 Real MySQL 8.0 - 9.3 인덱스 컨디션 푸쉬다운 (0) 2023.05.21 Real MySQL 8.0 8장 - 인덱스는 왼쪽이 중요하다. (0) 2023.03.26 Real MySQL 8.0 8장 - 인덱스 정렬 및 스캔의 방향 (0) 2023.03.26 Real MySQL 8.0 7장 - MySQL 암호화 (0) 2023.02.26